Accueil > Sommaire > Analyse ajustée
1 Introduction
Les analyses intermédiaires sont des analyses des données réalisées en cours d’essai, avant que tous les patients prévus aient été recrutés et/ou avant la fin de la période de suivi initialement prévue.
Au cours d’un essai, l’information s’accumule progressivement au fur et à mesure des inclusions et du suivi des patients. Mais c’est seulement au terme de l’essai, après avoir recruté l’effectif prévu et suivi les patients avec le recul prévu, que la quantité d’information est suffisante et que les données peuvent être analysées. Cependant, des analyses intermédiaires (« interim analysis ») à la recherche de l’effet du traitement en cours d’essai sont envisageables pour diverses raisons avant que tous les patients prévus aient été recrutés et/ou avant la fin de la période de suivi initialement prévue.
Par exemple, dans un essai devant recruter 300 patients avec un suivi d’un mois, deux analyses intermédiaires sont réalisées : la première après l’inclusion des 100 premiers patients, la seconde avec 200 patients. L’analyse finale porte, comme prévu, sur 300 patients. Dans un essai de 1000 patients avec un suivi de 5 ans, une analyse intermédiaire est réalisée après recrutement de l’ensemble des patients, mais à mi-parcours, c’est-à-dire avec un recul de 2,5 ans.
Le but de ces analyses intermédiaires est triple.
1. Le premier est de pouvoir détecter au plus tôt le bénéfice du traitement afin d’éviter de traiter des patients par un placebo alors que les données amassées sont suffisantes pour conclure à l’efficacité du traitement étudié (arrêt pour efficacité). De plus, la confirmation au plus tôt du bénéfice apporté par un traitement permet de faire bénéficier du traitement tous les patients hors essai le plus rapidement possible.
2. Le deuxième objectif est de se donner les moyens de détecter au plus tôt un éventuel effet délétère du traitement afin de limiter le nombre de patients exposés au risque (arrêt pour toxicité). Dans ces deux circonstances, le but des analyses intermédiaires est d’éviter de continuer à inclure des patients alors que l’on dispose d’une réponse suffisamment fiable à la question posée.
3. Le troisième objectif est d’arrêter une étude dont on peut prédire avec une certitude raisonnable qu’elle ne pourra pas aboutir (arrêt pour futilité). L’arrêt précoce permettra de diriger les ressources vers le test de nouvelles hypothèses.
La réalisation de ces analyses posent cependant un certain nombre de problèmes méthodologiques et nécessitent une méthodologie adaptée [1, 2]. Mais avant d’aborder l’exposé de ces problèmes et de leur solution, voyons les circonstances qui peuvent conduire à un arrêt prématuré d’un essai lors d’une analyse intermédiaire.
2
Situations conduisant à un arrêt
prématuré
Dans un chapitre précédent, nous avons vu que l’effectif d’un essai est le nombre de sujets minimal nécessaire pour garantir une probabilité élevée de mettre en évidence l’effet du traitement. Dans ce cas comment peut-on espérer, lors d’une analyse intermédiaire, pouvoir faire la même chose avec moins de patients ?
En fait, si l’effet réel du traitement est bien supérieur à l’effet initialement suspecté ou que le risque de base des patients inclus est bien supérieur à celui attendu, il sera possible de mettre en évidence l’effet du traitement avec moins de sujets que l’effectif prévu. Dans les deux cas, il y a eu sous-estimation de l’un ou de ces deux paramètres dans le calcul du nombre de sujets nécessaires et l’effectif initialement calculé est surdimensionné par rapport à la réalité.
Cette situation est imaginable car, assez
souvent, des données fiables manquent pour faire les hypothèses
du calcul du nombre de sujets. Il est alors envisageable que les valeurs
retenues soient éloignées de
3
Inflation du risque alpha
3.1 Exposé de la
problématique
La comparaison répétée de l’efficacité de deux traitements par des tests statistiques successifs accroît le risque de conclure à tort à la supériorité de l’un par rapport à l’autre.
La réalisation de plusieurs analyses statistiques dans la même expérience, pour tester la même hypothèse, conduit à des comparaisons statistiques multiples. À chaque analyse intermédiaire un test statistique est réalisé pour rechercher un effet du traitement. La répétition à chaque test du risque d’obtenir un résultat significatif par hasard augmente le risque global de conclure à tort à l’efficacité du traitement lors de cet essai. In fine le risque alpha n’est plus de 5% (même si c’est le seuil retenu pour chaque test) mais il est bien supérieure.
L’utilisation de techniques statistiques adaptées est nécessaire pour empêcher cette augmentation du risque alpha, appelée en jargon statistique « inflation du risque alpha ». Le but de ces méthodes est de garantir un risque global, sur l’ensemble des comparaisons effectuées, de conclure à tort à l’efficacité du traitement de 5%. Sur l’ensemble des comparaisons effectuées le risque d’obtenir au moins un résultat significatif par le fait du hasard est contrôlé et garde sa valeur prédéfinie de 5%.
3.2 Principe de la solution
Plusieurs solutions sont possibles qui sont à la base de différentes méthodes. L’une d’entre elles consiste à diminuer le seuil de signification statistique de chacune des comparaisons intermédiaires, par exemple en divisant le risque alpha global a par le nombre de comparaisons effectuées n. C’est la méthode de Bonferroni [3]. Ainsi malgré l’inflation du risque alpha, le risque final de conclure à tort à l’efficacité restera compris dans les valeurs habituelles.
Avec 3 analyses intermédiaires prévues, le nombre total de comparaisons qui seront effectuées est de 4 : les 3 intermédiaires plus la comparaison finale. Le seuil à utiliser pour chacune de ces analyses est de 5%/4=1,25%. Si un p inférieur à 1,25% est obtenu à l’une des analyses intermédiaires, il est alors possible de conclure et d’arrêter l’essai sans attendre la fin du recrutement prévu.
3.3 Études de cas
Cas 1. Dans la situation dépeinte par le tableau ci dessous, l’essai peut être arrêté à la 2ème analyse intermédiaire. Le p obtenu lors de cette analyse est inférieur au seuil de signification corrigé et l’essai peut donc être arrêté prématurément. Cette situation met en avant tout l’intérêt des analyses intermédiaires.
|
Analyses intermédiaires |
Analyse |
||
|
1 |
2 |
3 |
|
|
p = 0,10 |
p = 0,011 |
|
|
Cas 2. Dans ce deuxième exemple, le p<5% de la troisième analyse intermédiaire ne permet pas de conclure à une différence significative car la valeur obtenue reste supérieure au seuil corrigé pour 4 tests (1,25%). L’essai va donc à son terme et lors de l’analyse finale le p devient inférieur au seuil corrigé ce qui donne donc finalement un résultat statistiquement significatif.
|
Analyses intermédiaires |
Analyse |
||
|
1 |
2 |
3 |
|
|
p = 0.25 |
p = 0.08 |
p = 0.04 |
P = 0.012 |
Cas 3. Le cas suivant peut paraître déroutant. Aucune analyse intermédiaire ne conduit à interrompre prématurément l’essai. Lors de l’analyse finale un p de 4% est obtenu. Cette valeur, bien qu’elle soit inférieure à 5% n’autorise pas à conclure à un résultat statistiquement significatif car elle reste supérieure au seuil corrigé. Il ne peut pas être considéré comme significatif car du risque alpha a été consommé au cours des analyses précédentes, effritant le contrôle du risque d’erreur de première espèce apporté par un p<5% au niveau d’une comparaison donnée (le coté gênant de ce résultat a conduit au développement d’une méthode qui évite de se retrouver dans cette situation, la méthode de Peto, cf. infra)
|
Analyses intermédiaires |
Analyse |
||
|
1 |
2 |
3 |
|
|
p = 0,42 |
p = 0,28 |
p = 0,12 |
p = 0,04 |
Cas 4. Dans le dernier cas de figure, aucune analyse n’atteint le seuil corrigé de signification statistique. L’essai n’obtient donc pas de résultat statistiquement significatif.
|
Analyses intermédiaires |
Analyse |
||
|
1 |
2 |
3 |
|
|
P = 0,89 |
p = 0,48 |
p = 0,25 |
p = 0,10 |
3.4 Le côté
paradoxal du cas n°3
Le cas n° 3 est un peu perturbant. A la dernière analyse, le p de 4% de la dernière analyse ne permet pas de conclure alors que s’il avait été obtenu sans aucune analyse intermédiaire l’essai serait concluant !
En fait, 4% à l’issu d’un seul test à la fin d’un essai ce n’est pas la même chose qu’un 4% à la 4ème analyse car dans ce dernier cas il y a eux les 3 autres tests.
Pour mieux comprendre cela, nous allons faire du dénombrement.
En ne faisant qu’une et une seule analyse en fin d’étude, sur 100 essais réalisés avec un traitement sans effet, quel est le nombre d’essais permettant de conclure à tort à l’efficacité ? C’est 5 (pour un seuil de signification de 5%) par définition du risque alpha. Le risque effectif de conclure à tort est donc bien celui que l’on attend (5/100).
Toujours avec un traitement sans effet, mais en faisant 3 analyses intermédiaires et une analyse finale (soit 4 analyses au total), combien avons-nous de possibilités d'obtenir un résultat concluant (c'est à dire d’obtenir un résultat significatif au 1er test OU au 2ème OU au 3ème OU au 4ème et dernier test.) :? Le calcul est un peu plus fastidieux. C’est 5 au premier test (5% des 100 essais initiaux) puis c'est, au deuxième test, 5% des 95 essais qui n'ont pas été significatifs au premier (soit 4.75), puis 5% des 100-5-4.75=90.25 essais qui n'ont pas été significatifs à la première et à la seconde analyse intermédiaire soit 5.5125, etc. (cf tableau ci dessous)
Au total, en procédant de cette façon, sur 100 essais il y a en aura 18,5 qui donneront une possibilité de conclure à l’efficacité du traitement (soit lors de la 1er analyse intermédiaire, soit lors de la seconde, soit etc.). Le risque globale d’erreur de 1er espèce est donc de 18,5/100 soit 18,5%, bien supérieur au 5% que l’on est prêt à consentir.
|
Nombre d'essais arrivant à l'AI |
Nb de résultats significatifs à l'AI (tests avec un seuil de 5%) |
Cumul des conclusions à l'efficacité |
|
|
1 |
100 |
5 |
5 |
|
2 |
95 |
4.75 |
9.75 |
|
3 |
90.25 |
4.51 |
14.26 |
|
4 (Analyse finale) |
85.74 |
4.29 |
18.55 |
Une méthode de Bonferroni permet de solutionner ce problème. En prenant comme seuil pour les tests 5%/4=1.25% ont obtient le décompte suivant :
|
Analyse intermédiaire (AI) n° |
Nombre d'essais arrivant à l'AI |
Nb de résultats significatifs à l'AI (tests avec un seuil de 1.25%) |
Cumul des conclusions à l'efficacité |
|
1 |
100 |
1.25 |
1.25 |
|
2 |
98.75 |
1.23 |
2.48 |
|
3 |
97.52 |
1.22 |
3.70 |
|
4 (Analyse finale) |
96.30 |
1.20 |
4.91 |
Ainsi, en exigeant pour conclure à l’efficacité d’avoir un p inférieur à 1.25% à une de ces 4 analyses, on obtiendra sur 100 essais que 4,9 essais concluants. Ce qui donne un risque d’erreur global de 1er espèce de 4,9/100=4,9% proche des 5% recherché. En fait, la méthode de Bonferroni est conservatrice car elle autorise légèrement moins de conclusion à tort que ce que l'on est prêt à accepter.
4
p global
Dans les cas 1 et 2, les valeurs numériques de p obtenues lors des tests ne peuvent pas être retranscrites comme telle. Par exemple, dans le cas 1 il n’est pas possible de dire qu’un résultat significatif avec p=0,011 a été obtenu. La procédure utilisée ne garantit que le risque alpha de la conclusion globale, et non pas celle de chaque comparaison. la conclusion correcte est de dire que dans le cas 1 un résultat statistiquement significatif a été obtenu avec p<5%. Des techniques statistiques spécialisées peuvent être utilisées pour estimer le p global qui dans l’exemple 1 sera proche de 5%.
Ce point complique aussi le calcul d’un intervalle de confiance. L’intervalle de confiance à 95% calculé directement est trop étroit. De la même façon que l’on utilise un seuil de risque alpha plus petit que 5% à chaque comparaison, il est nécessaire de prendre un niveau de confiance plus élevé qui pourrait être en première approximation (100%-1,25% = 98,75%). En effet, d’après le lien existant entre test statistique et intervalle de confiance, l’intervalle de confiance de 98,75% correspond à un test réalisé avec un seuil de signification de 1,25%. Là aussi des techniques statistiques adaptées existent pour calculer les intervalles de confiances.
5
Les différentes méthodes
La première méthode proposée (Pocock) utilisait un seuil constant à chaque analyse [4] et était une application de la méthode de Bonferroni aux analyses intermédiaires. Cette stratégie n’est plus conseillée actuellement car elle conduit à interrompre trop facilement un essai peu de temps après son démarrage. Elle expose aussi à la situation du cas n°3 de l’étude de cas précédente (cf. supra). Pour éviter ces écueils, les autres méthodes utilisent des seuils de signification croissants au cours des analyses intermédiaires. Par exemple, dans la méthode de O’Brien et Flemming les seuils sont très faibles au moment des premières analyses [5].
Le précédent cas n°3 peut apparaître paradoxal.
Lors de l’analyse finale le p de 4% ne permet pas de conclure à un
résultat statistiquement significatif. Pourtant si aucune analyse
intermédiaire n’avait été réalisée,
ces données auraient conduit à un résultat statistiquement
significatif. Même si la conclusion adaptée s’explique par
l’inflation du risque alpha, la publication d’un résultat
final d’essai où l’on conclut à un résultat
non significatif avec un p de 4% risque d’être mal comprise et
interprétée. Pour éviter cette situation, Peto et Haybittle ont proposés une
méthode où les comparaisons intermédiaires
s’effectuent avec un seuil très bas (de l’ordre de 0,001) [6], ce qui consomme peu de
risque alpha et permet de prendre un seuil très proche de 5% pour
l’analyse finale. Avec cette méthode, un essai ne peut être
interrompu prématurément que si on obtient un résultat
très hautement significatif lors d’une analyse
intermédiaire, c’est-à-dire si l’effet réel
s’avère très supérieur à celui attendu.
D’autres
méthodes, en particulier celles proposées par Lan et Demets [7], sont intermédiaires
entre celles de Peto- Haybittle et de Pocock (tableau 1). La méthode de Peto- Haybittle est
actuellement très prisée. D’autres approches statistiques
ont été proposées. L’approche du stochastique
curtailment a pour principe d’extrapoler, à partir des
résultats observés lors d’une analyse intermédiaire,
ce que pourrait être le résultat final de l’essai et de
calculer les probabilités d’obtenir une différence
significative sous différentes hypothèses d’effet du
traitement. Des méthodes bayesiennes ont également
été proposées 19. Armitage P. Interim analysis in clinical
trials. Stat Med 1991;10:925-37.
Tableau 1 – Comparaison des différentes méthodes
|
|
Analyses intermédiaires |
Analyse finale |
|||
|
|
1 |
2 |
3 |
4 |
|
|
0,017 |
0,017 |
0,017 |
0,017 |
0,017 |
|
|
O’Brien et Flemming |
0,00005 |
0,004 |
0,012 |
0,025 |
0,04 |
|
Lan et Demets 1 |
0,015 |
0,016 |
0,017 |
0,018 |
0,019 |
|
Lan et Demets 2 |
0,00001 |
0,002 |
0,011 |
0,025 |
0,041 |
|
Peto - Haybittle |
0,001 |
0,001 |
0,001 |
0,001 |
0,05 |
Exemple
”The data and safety monitoring board monitored the incidence of
the primary outcome to determine the benefit of clopidogrel, using a modified Haybittle–Peto
boundary of 4 SD in the first half of the study and 3 SD in the second half of
the study. The boundary had to be exceeded at two or more consecutive time
points, at least three months apart, for the board to consider terminating the
study early. There were two formal interim assessments performed at the times
when approximately one third and two thirds of the expected events had
occurred.”
6
Les deux monitorages
L’objectif des analyses
intermédiaires étant double, deux surveillances sont
réalisées simultanément : celle de
l’efficacité (« efficacy »)
et celle de la sécurité (« safety »). Un essai
pouvant être arrêté prématurément soit par la
surveillance de l’efficacité soit par celle de
Exemple
« The protocol specified that the independent data and safety monitoring
board would undertake an interim analysis when 25%, 50%, and 75% of the total
anticipated primary endpoints had accrued. The interim analyses used an asymmetric
(Peto-Haybittle) type rule and we prespecified that the board might advise
termination if a significant difference emerged in favour of atorvastatin (at
p<0·0005 one-sided, p<0·001 twosided at any analysis) or in
favour of placebo (at p<0·005, 0·1, and 0·2 one-sided,
for the three interim analyses, respectively). »
7
Autres objectifs des analyses intermédiaires
Les analyses intermédiaires s’intègrent dans un processus global de surveillance des essais. À coté de la recherche anticipée d’un effet du traitement et de la protection des personnes incluses dans l’essai, cette surveillance a pour objectif de vérifier le bon déroulement de l’essai. Il s’agit d’éviter des dérives dans la réalisation de l’essai, qui, si elles n’étaient détectées qu’à la fin, rendraient l’essai inutilisable en raison de défauts de qualité rédhibitoires.
Les éléments à surveiller sont les suivants :
· le taux d’écart au protocole : l’essai est-il de qualité ?
· le taux d’inclusion : est-ce que l’essai pourra être réalisé dans un délai acceptable ?
· les caractéristiques des patients inclus : le risque de base des patients effectivement inclus correspond t-il à celui initialement prévu et utilisé dans le calcul du nombre de sujets nécessaire ? Les patients recrutés correspondent-ils à la population cible de l’essai ?
Cette surveillance permet de prendre au plus tôt des mesures correctrices. Les centres investigateurs ayant des difficultés à suivre le protocole pourront rectifier le tir. En cas de taux de recrutement insuffisant, d’autres centres investigateurs pourront être recrutés afin d’éviter qu’un essai dure trop longtemps. En effet, une durée excessive limite l’intérêt d’un essai.
Cette surveillance par analyse des données amassées se superpose à la surveillance « de terrain » de l’essai (appelé parfois « monitorage ») qui est focalisée sur le contrôle de qualité des données (visite de centres, contrôles des données, audit).
8
Les analyses intermédiaires en pratique
La réalisation d’une analyse statistique implique la levée de l’insu. Une organisation particulière est donc nécessaire pour éviter que la réalisation d’analyses intermédiaire perturbe la réalisation de l’essai en double insu et conduise à l’introduction de biais. En particulier le résultat de ces analyses doit rester inconnu de toutes les personnes impliquées dans la réalisation de l’essai : investigateur, personnels de coordinations, promoteurs. En effet, la divulgation des résultats des analyses intermédiaires pourrait avoir de nombreuses conséquences délétères pour l’essai : arrêt des inclusions en cas de tendance favorable et utilisation en pratique d’un traitement sans que la démonstration de l’efficacité n’ait pu être obtenue.
En pratique, les analyses intermédiaires sont réalisées par une structure indépendante de la coordination de l’essai. Les résultats de l’analyse sont communiqués à un comité de surveillance (« safety committee , Independent Data Monitoring Committee (IDMC), Data and Safety Monitoring Board (DSMB), Monitoring Committee, Data Monitoring Committee ») composé de personnes indépendantes. Ce comité émettra au vu des résultats des analyses statistiques une recommandation destinée au comité directeur de l’essai. Cette recommandation peut être de poursuivre le recrutement, d’interrompre l’essai à ce stade, de modifier le protocole.
9
Les analyses séquentielles
Les méthodes séquentielles permettent de répéter de nombreuses fois en cours d’essais la comparaison statistique et d’arrêter l’essai dès qu’il est possible de rejeter l’hypothèse nulle. L’analyse séquentielle est équivalente à la réalisation de nombreuses analyses intermédiaires. À chaque nouvelle paire de patients (un patient traité avec le traitement étudié et un avec le traitement contrôle) on calcule une nouvelle valeur du test que l’on compare à une valeur maximum et une valeur minimale. Si la valeur maximale est dépassée, on rejette l’hypothèse nulle. Si la valeur est inférieure à la valeur minimum, on rejette l’hypothèse alternative ce qui permet de conclure à l’équivalence à un delta après. Dans ces deux cas, l’essai s’arrête. Tant que la valeur du test reste entre ces deux limites, on continue à recueillir des observations.
La réalisation de cette approche repose en pratique sur un graphique représentant les limites de décision sous forme de triangle (figure 1). Pour cela la méthode est appelé test triangulaire.
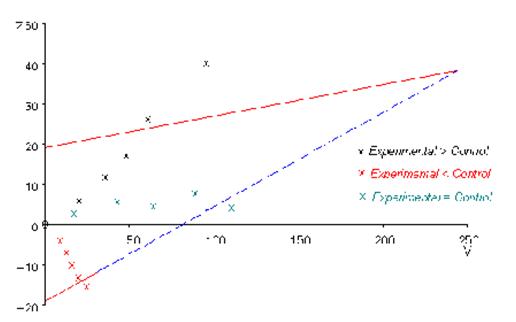
Figure 1- Représentation graphique du test triangulaire qui est un type d’analyse séquentielle.
Un inconvénient est que la méthode suppose que l’observation de la paire précédente soit terminée quand, est admise dans l’essai, la paire de patients suivante. Cela implique en pratique que la durée d’observation soit courte par comparaison à l’intervalle entre les admissions des sujets dans l’essai.
Un des avantages des analyses séquentielles est de permettre de conclure en moyenne avec moins de sujets qu’une approche classique. L’autre intérêt est l’assurance d’arrêter l’essai au plus tôt dès que la preuve de la supériorité d’un des traitements comparés est atteinte.
Dans de nombreux cas, l’analyse séquentielle est utilisée sous forme d’analyses séquentielles groupées : l’analyse n’est pas réalisée à chaque paire de patients mais après l’inclusion d’un petit nombre de patients.
1
Lecture critique et l’interprétation
Les questions à se poser lors de la lecture critique sont les suivantes en ce qui concerne les analyses intermédiaires :
· Si plusieurs analyses successives du même essai ont été réalisées, est-ce que ces analyses étaient de véritables analyses intermédiaires prévues a priori et utilisant une méthode de protection contre les risques des comparaisons multiples ? Pour le lecteur non statisticien il est difficile de juger de la méthode utilisée. D’une manière générale, toutes les méthodes couramment utilisées sont satisfaisantes. Il suffit donc de vérifier de le chapitre analyses statistiques précise bien l’utilisation d’une méthode sans qu’il soit utile de rentre dans les détails.
· Le p rapporté est-il correct ? Est-ce le p trouvé directement au niveau d’une des la comparaison ou le seuil de signification statistique ajusté pour tenir compte de l’ensemble des comparaisons ?
· Si des intervalles de confiance sont rapportés, sont-ils corrigés pour prendre en compte l’inflation du risque alpha ?
2 Pour en savoir plus
[8]
3 Bibliographie
1. Buyse M. Interim analyses, stopping
rules and data monitoring in clinical trials in Europe. Stat Med
1993;12(5-6):509-20. PMID:
2. Pocock
SJ. When to stop a clinical trial. BMJ 1992;305(6847):235-40. PMID:
3. Bland
JM, Altman DG. Multiple significance tests: the Bonferroni method. BMJ
1995;310:170. PMID:
4. Pocock
SJ. Group sequential methods for clinical trials. Biometrics 1977;35:549-56. PMID:
5. O'Brien
PC, Fleming TR. A multiple testing procedure for clinical trials. Biometrics
1979;35:549-56. PMID:
6. Peto R,
Pike MC, Artmitage P. Design and analysis of randomized clinical trials
requiring prolonged observation of each patients. Br J cancer 1976;34:585-612. PMID:
7. Lan
KKG, Demets DL. Discrete sequential boundaries for clinical trials. Biometrika
1983;70:659-63. PMID:
8. Mueller
PS, Montori VM, Bassler D, Koenig BA, Guyatt GH. Ethical issues in stopping
randomized trials early because of apparent benefit. Ann Intern Med
2007;146(12):878-81. PMID: 17577007.
Interprétation
des essais cliniques pour la pratique médicale
www.spc.univ-lyon1.fr/polycop
Faculté de Médecine Lyon - Laennec
Mis à jour : aout 2009